Organizations are now using Splunk for enterprise-wide, multi-use case, silo-smashing projects. It is often the department or team with the most Splunk experience that champions the initiative and leads the organization down a path of an Enterprise Adoption Agreement, or larger license to meet a broader set of requirements.
Whether these initiatives are tied to a Center of Excellence (CoE), Splunk as a Service offering, or simply the natural progression of Splunk adoption, it becomes very important to understand how different parts of the organization are using Splunk from a license and infrastructure standpoint. This understanding is critical to supporting the growth of the Splunk environment and essential to implementing a chargeback or cost recovery program. We created dvvy to provide this insight.
dvvy is a Splunk app that lays a foundation for your Splunk chargeback or cost-recovery initiative. It will quantify how your organization uses Splunk and will help you cultivate funds for continued use and expansion.
Mechanics

dvvy measures key dimensions of Splunk usage by data source and calculates charges based on that usage. This measurement and calculation is accomplished with straightforward and familiar Splunk mechanics. Saved searches fire against the _internal index to track license usage by index and source type. The dbinspect search command is used for index storage. In turn, jobs run nightly to calculate the charges for license, hot/warm storage, and cold storage. All of the utilization and charge calculations are written to summary indexes.
Additionally, indexer charges are calculated based on your configured daily indexing target. indexerTargetGB is a value you define in the app configuration that represents your optimal daily index volume based on your indexer horsepower (i.e., I/O, CPU, memory) and Splunk app mix. If the value is set to 300 GB and a source type’s daily indexing volume is 150 GB, the data source is consuming approximately half of an indexer’s resources and charges are calculated accordingly. This simple approach provides an approximation of indexer resources based on your sizing and architectural constraints.
We are at work on additional measurement techniques and chargeback dimensions, including the evaluation of user search load, staffing costs, and more granular capabilities around data ownership.
Configuration
The dvvy app is easy to deploy and provides considerable flexibility through its data source, group, cost center, and entitlement configuration.
Data Sources
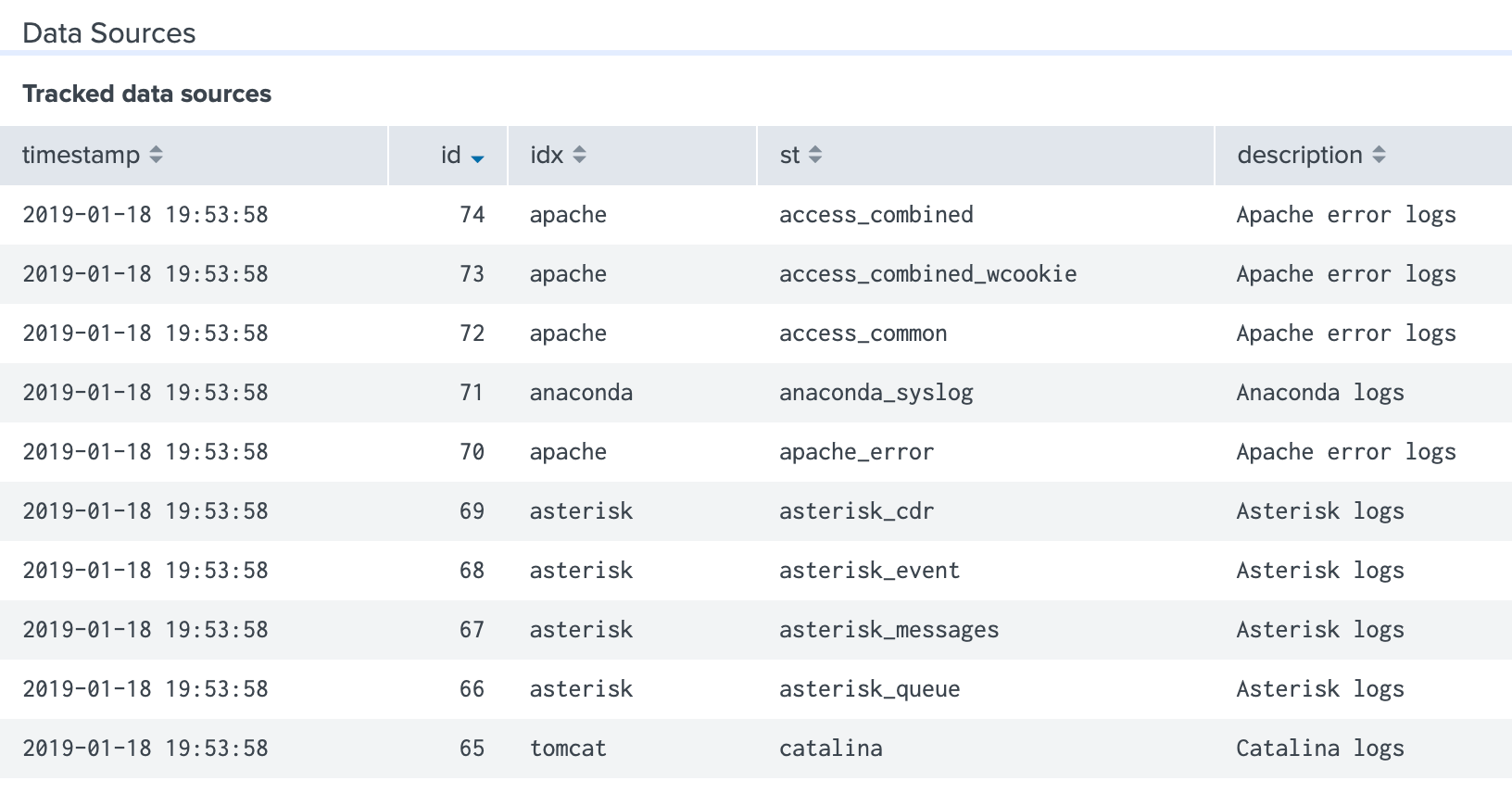
Data sources must be explicitly added to dvvy in order to track utilization and calculate charges. While you can add every data source, we understand that some data in your environment may fall outside of the scope of your chargeback initiative. Such data may belong to the Splunk application owner or perhaps it’s widely used without clear ownership. This data is easily excluded by simply not adding the index and source type to the dvvyData collection.
The fields required for app operation are timestamp, id, idx, st, and group. For more comprehensive reporting and additional context populate the costCenter, tag, useCase, and description fields.
Adding data can be done by importing a csv file or running a search with outputlookup. We provide a search in the dvvy Admin Guide to get you started. Populating the optional fields will require more legwork upfront, but from a technical standpoint it’s easily accomplished with a lookup.
Groups
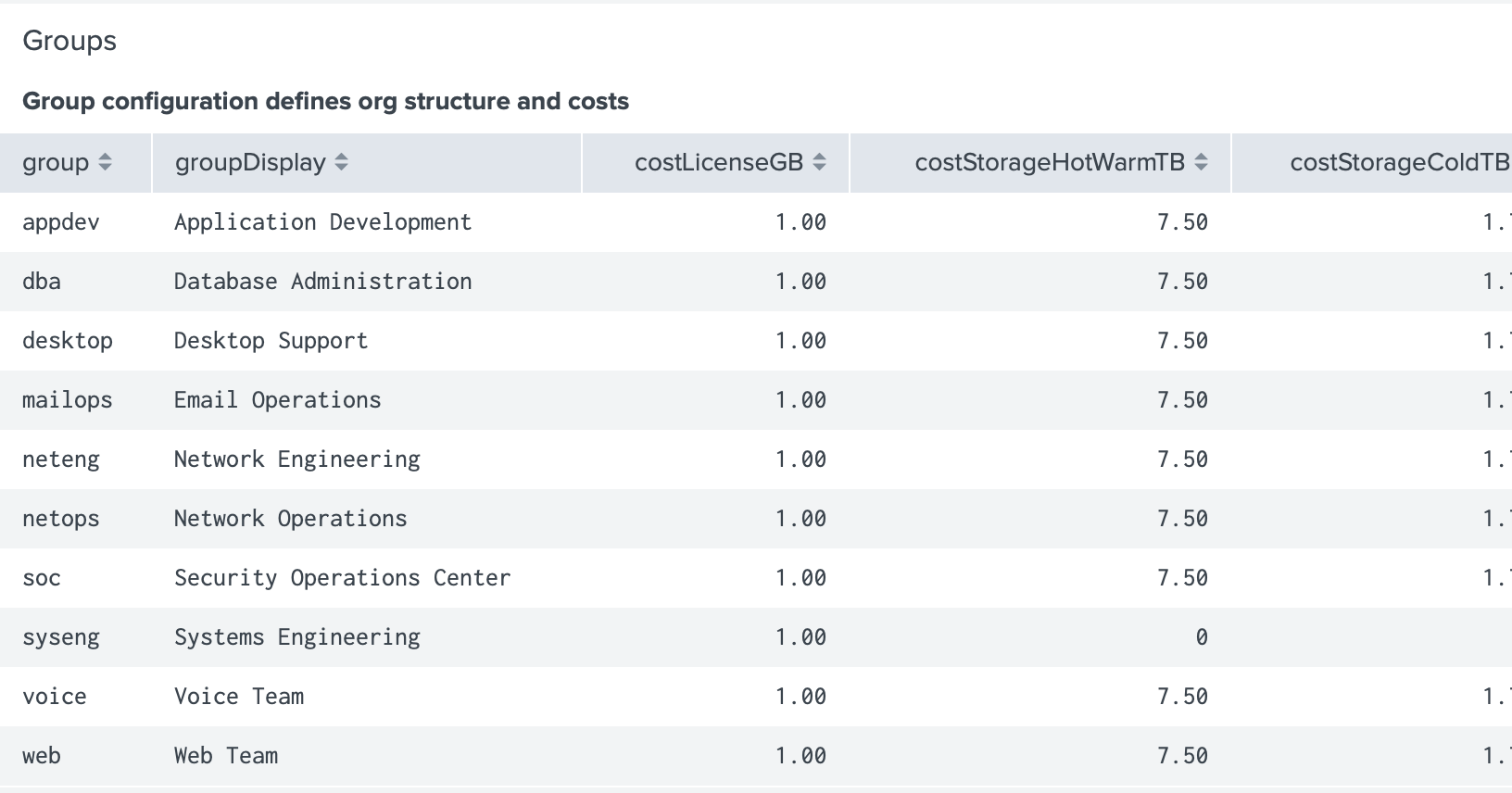
dvvy allows you to define groups that mirror the structure of your organization for the purpose of charge calculation. Every data source tracked by dvvy is associated with a group to establish ownership. In dvvy-speak, a group might be a department, team, line of business, division, or other organizational unit that’s meaningful to you. Costs for license, storage, and indexer resources are defined per group which gives you quite a bit of flexibility.
Consider the following scenario with dvvy configuration thusly:
Example Scenario
The Foo, Inc. Security Operations Center (SOC) acquired a 1 TB Splunk license for use by multiple departments, including the Network Operations Center (NOC), Systems Engineering, Network Engineering, and the Voice Team.
- The SOC covered the license from their IT budget, so they shouldn’t be charged for license. However, the shiny new Splunk instance is running on infrastructure provided by Systems Engineering. Management decides that Systems Engineering should be reimbursed by all of the departments using Splunk.
costLicenseGB: 0 costIndexer: $x costStorageHotWarmTB: $y costStorageColdTB: $z - Systems Engineering ponied up the servers and storage, so they should only be charged for license usage.
costLicenseGB: $x costIndexer: 0 costStorageHotWarmTB: 0 costStorageColdTB: 0 - The Voice Team is a newly formed team below Network Engineering without their own budget. Management still wants to track their usage but doesn’t want dollars to change hands for the time being.
costLicenseGB: 0 costIndexer: 0 costStorageHotWarmTB: 0 costStorageColdTB: 0 - The NOC and Network Engineering are purely consumers of Splunk license and infrastructure so it’s decided that they should be charged for all dimensions. Although it should be pointed out that different costs can be applied per group, so if the NOC negotiated a different per-GB rate for license it could easily be setup.
costLicenseGB: $a costIndexer: $b costStorageHotWarmTB: $c costStorageColdTB: $d
Cost Centers
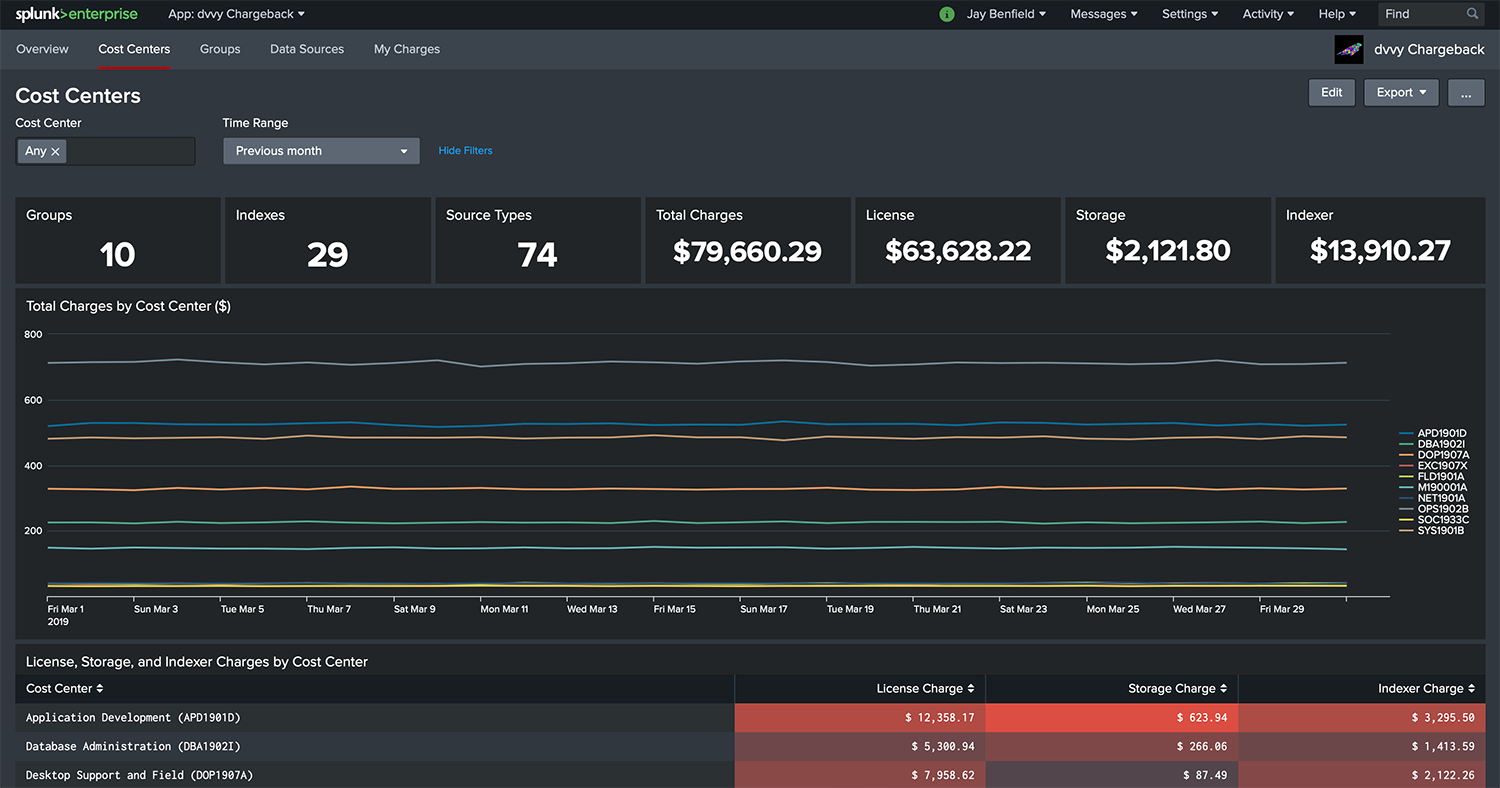
Data sources can optionally be associated with a cost center. Cost centers enable an additional layer of reporting from an accounting standpoint. Continuing our example:
- Foo, Inc. management tracks IT-related expenses in two primary accounting buckets: operations and engineering. All of the SOC and NOC data sources are associated with the operations cost center (OPS2019). The Systems Engineering, Network Engineering, and Voice Team data sources are associated with the engineering cost center (ENG2019). In turn, the Cost Centers dashboard gives Foo management this visibility across group boundaries.
If you don’t need cost center reporting, consider using this functionality to add another meaningful dimension to your data. This dimension could be some type of internal reference number, or perhaps parent org names to establish some reporting hierarchy. The latter works because a cost center can straddle multiple groups.
Resource Entitlements
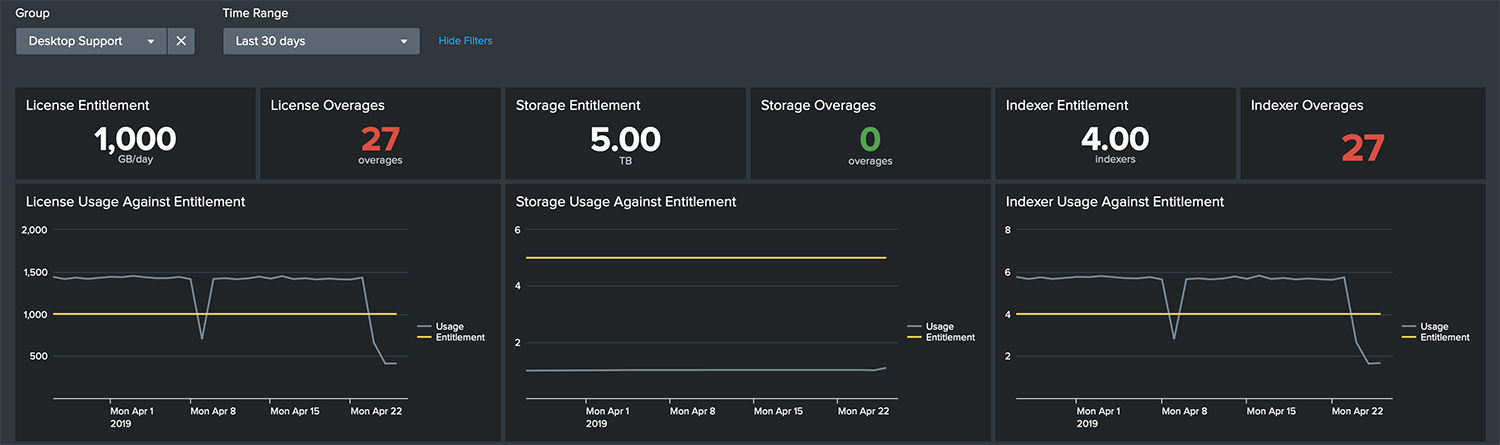
You are able to define entitlements for license, storage, and indexer resources for each group. And back to Foo:
- The Foo, Inc. SOC had done their due diligence before investing in the 1 TB license. They conducted a data call with all of the stakeholders and determined how much license each required in the current budget cycle. They needed 600 GB for themselves, but the remainder was to be divvied up between the other parts of the company resulting in a license entitlement of 100 GB for each group.
- The admins subsequently set the
licenseEntitlementGBvalue to 100 which allows the SOC, and users from every group, to easily see where they stand on ingest from day to day. - A storage entitlement may also be defined and the indexer entitlement is automatically calculated relative to
indexerTargetGB.
Dashboards
dvvy’s dashboards provide usage and charge details relating to license, storage, and indexer resources from three key vantage points: data source, group, and cost center.
The data presented in the app is scoped by the user’s group affiliation. If a user is listed as an adminContact or techContact for both the NOC and SOC, she will have access to the utilization and charge information of all data sources belonging to the two groups. Admins have access to all data and users not associated with a group will be able to access the app, but the dashboards will be blank. This is accomplished with logic in each dashboard and not with access controls at the index level. You are welcome to implement additional controls on the summaries as you see fit.
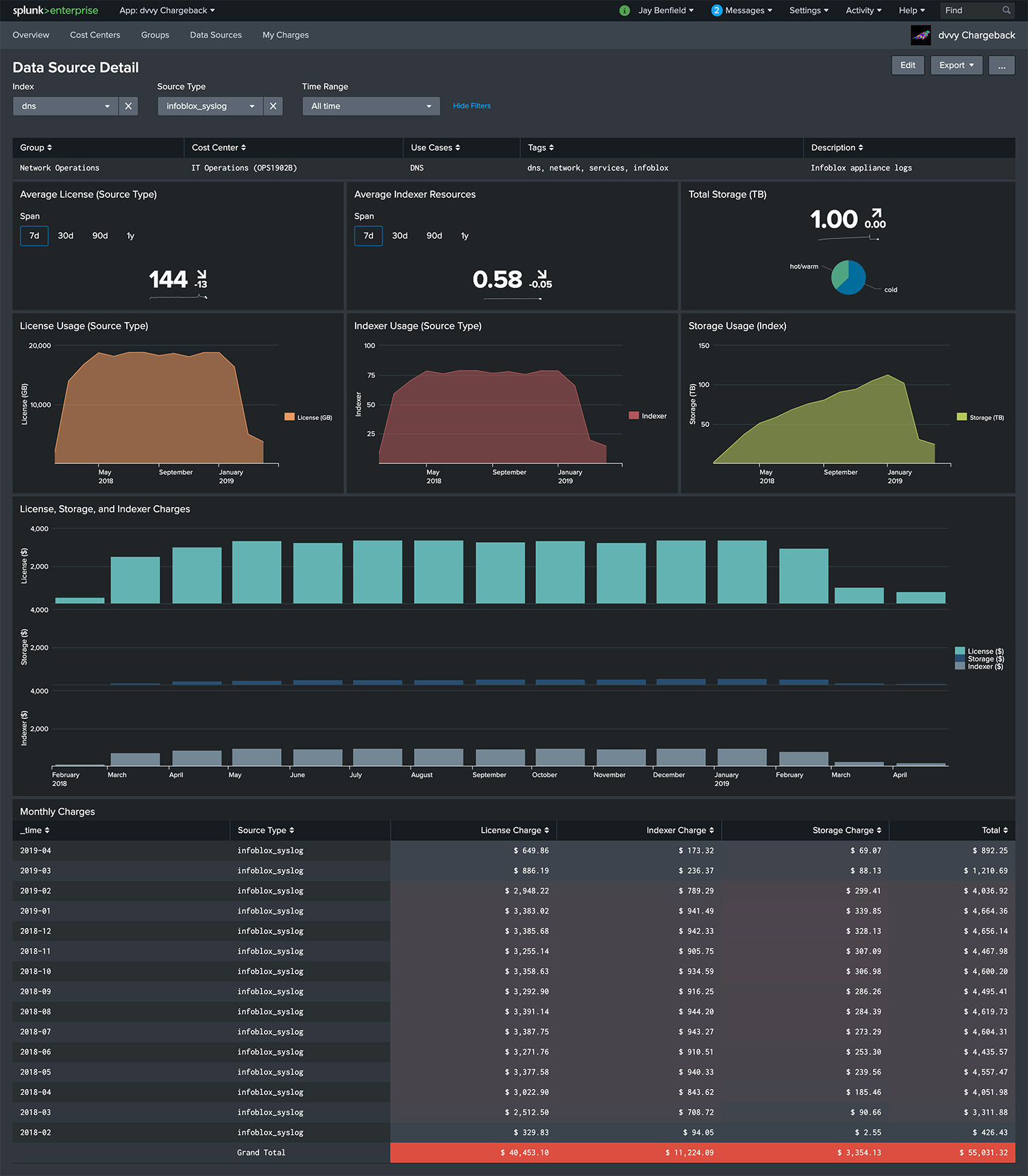
Below is the Data Source Detail dashboard, which provides details relating to a specific source type. It shows information about the data source, utilization data, and a monthly roll-up of charges. This is useful in assessing the financial and infrastructure impact of a specific source.
Next Steps
If you would like to see more, please contact us for a demo. The dvvy app is also available for download on Splunkbase. After downloading, request a free 30-day trial license to evaluate the app. Email sales@redfactorapps.com or request a quote.
Are you attending Splunk GovSummit in DC on May 9th? Come see a dvvy demo at the Carahsoft booth in the Solution Showcase from 10:15 AM – 10:45 AM.
About the Author
Post by Jay Benfield
Jay Benfield is the Founder of RedFactor. Previously a longtime Splunker and Splunk customer, he thrives on solving problems with the Splunk platform and is passionate about customer success.
More posts by Jay Benfield